简单快速的对象存储库:Paper(二)
在前面简单快速的对象存储库:Paper(一)中介绍了Paper库及其简单使用,Paper库代码不多,源码也易于阅读,主要理解其设计。简要概括Paper设计如下:

1、获取Book实例
开发者无需关注Book实例的构造,只需通过Paper提供的几个方法获取Book实例:
①获取指定名称的Book,不能使用内部保留名称DEFAULT_DB_NAME
public static @NonNull Book book(@NonNull String name) {
if (name.equals(DEFAULT_DB_NAME)) throw new PaperDbException(DEFAULT_DB_NAME +
" name is reserved for default library name");
return getBook(null, name);
} ②获取默认DEFAULT_DB_NAME名的Book实例
public static @NonNull Book book() {
return getBook(null, DEFAULT_DB_NAME);
} ③指定Book存储位置,使用默认DEFAULT_DB_NAME名
public static @NonNull Book bookOn(@NonNull String location) {
return bookOn(location, DEFAULT_DB_NAME);
} ④指定location和name
public static @NonNull Book bookOn(@NonNull String location, @NonNull String name) {
location = removeLastFileSeparatorIfExists(location);
return getBook(location, name);
} 所有获取Book的公共方法最终都会走到一个私有的getBook()方法统一处理:
private static Book getBook(String location, String name) {
if (mContext == null) {
throw new PaperDbException("Paper.init is not called");
}
//根据location和name创建Book唯一key
String key = (location == null ? "" : location) + name;
synchronized (mBookMap) {
//从hash缓存中获取对应name的Book实例
Book book = mBookMap.get(key);
//没有缓存,则创建对象
if (book == null) {
if (location == null) {
//未指定location目录,会通过Context获取应用内部file路径
book = new Book(mContext, name, mCustomSerializers);
} else {
//使用指定的路径,注意读写权限
book = new Book(location, name, mCustomSerializers);
}
//将新建的Book放入到hash缓存中
mBookMap.put(key, book);
}
return book;
}
} 内部使用hash映射缓存Book对象:
private static final ConcurrentHashMap<String, Book> mBookMap = new ConcurrentHashMap<>();
2、通过Book读写
越优秀的库,往往只需要最简单的调用,从Glide、LeakCanary等开源库中也能体会到这一点。
2.1、读/写
①通过Paper写入一条数据
Paper.book().write("name", "Quibbler");
//流程图和下面的类似,为了方便生成时序图,使用下面的方法追踪
Paper.put("name", "Quibbler"); 写操作是通过DbStoragePlainFile完成的:
public @NonNull <T> Book write(@NonNull String key, @NonNull T value) {
//在这里校验写入的值,不可以为null
if (value == null) {
throw new PaperDbException("Paper doesn't support writing null root values");
} else {
mStorage.insert(key, value);
}
return this;
} 每次读写都会根据当前key从KeyLocker获取对应的Semaphore信号量用于线程同步,因此对同一个key的读写是线程安全的:
<E> void insert(String key, E value) {
try {
//获取当前key对应的Semaphore锁,同时在此方法中校验key不为null
keyLocker.acquire(key);
assertInit();
final PaperTable<E> paperTable = new PaperTable<>(value);
//写之前,文件的备份
final File originalFile = getOriginalFile(key);
final File backupFile = makeBackupFile(originalFile);
// 重命名当前文件,以便在下次读取时用作备份
if (originalFile.exists()) {
//将原始文件重命名为备份文件
if (!backupFile.exists()) {
if (!originalFile.renameTo(backupFile)) {
throw new PaperDbException("Couldn't rename file " + originalFile
+ " to backup file " + backupFile);
}
} else {
//如果备份存在 -> 意味着原始文件已损坏,必须删除
originalFile.delete();
}
}
//写文件
writeTableFile(key, paperTable, originalFile, backupFile);
} finally {
keyLocker.release(key);
}
} 最后通过writeTableFile()方法将对象写入文件,这里用到了另一个库:Kryo,一个快速、高效、自动的序列化工具。
private <E> void writeTableFile(String key, PaperTable<E> paperTable,
File originalFile, File backupFile) {
...
try {
FileOutputStream fileStream = new FileOutputStream(originalFile);
kryoOutput = new Output(fileStream);
//通过Kryo序列化对象,写入到文件中
getKryo().writeObject(kryoOutput, paperTable);
kryoOutput.flush();
fileStream.flush();
sync(fileStream);
...
} catch (IOException | KryoException e) {
...
}
} 用SequenceDiagram一键生成的时序图如下:
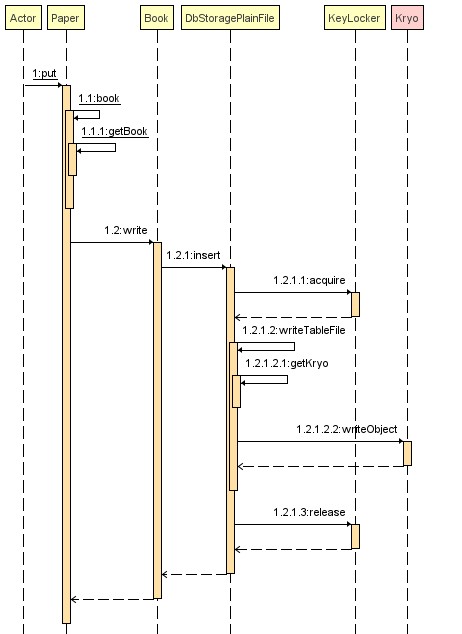
②通过Paper查询一条数据
String name = Paper.book().read("name", "defalut");
//流程图和下面的类似,为了方便生成时序图,使用下面的方法追踪
String name = Paper.get("name", "defalut"); 代码就不再 CV 了,时序图如下:
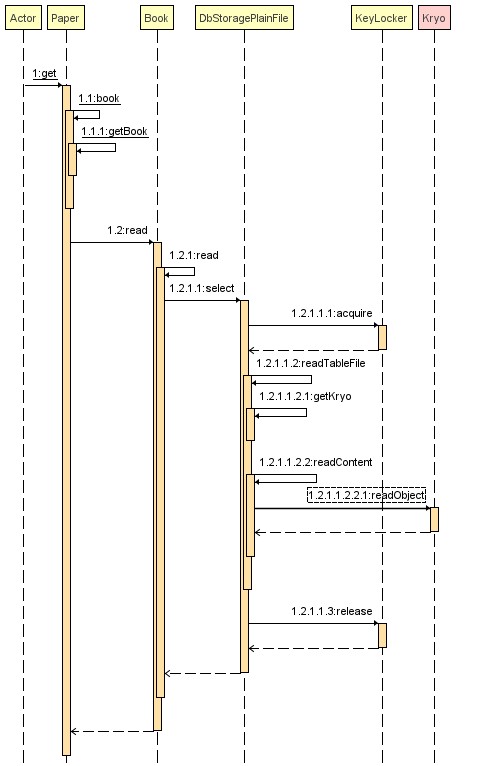
2.2、废弃的方法*
查看GitHub上的提交记录,可以发现从一开始此库就废弃了所有直接通过Paper进行读写操作的方法,只是从2015年到现在都没有删除:
/**
* @deprecated use Paper.book().write()
*/
public static @NonNull <T> Book put(@NonNull String key, @NonNull T value) {
return book().write(key, value);
}
/**
* @deprecated use Paper.book().read()
*/
public static @Nullable <T> T get(@NonNull String key) {
return book().read(key);
}
/**
* @deprecated use Paper.book().read()
*/
public static @Nullable <T> T get(@NonNull String key, @Nullable T defaultValue) {
return book().read(key, defaultValue);
}
/**
* @deprecated use Paper.book().contains()
*/
public static boolean exist(@NonNull String key) {
return book().contains(key);
}
/**
* @deprecated use Paper.book().delete()
*/
public static void delete(@NonNull String key) {
book().delete(key);
} 可以理解作者的用意,当初这样确实能够方便开发者。但是从设计的角度来说,需要让开发者知道中间Book层的存在:
Paper.put("number", 10058); Paper库类似NoSql存储,如果全都put到默认的Book中,读写性能反而会降低。
Paper.book("cn.quibbler").write("number", 10058);