本地大语言模型AI工具:Ollama
Ollama是一个强大的AI模型运行工具,开源地址:github/ollama。可以方便的在本地部署开源模型,避免数据泄露。
易于安装和使用:Ollama 支持 macOS、Windows 和 Linux,提供了简洁明了的安装和运行指令,让用户无需深入了解复杂的配置即可启动和运行。
丰富的模型库:通过Ollama,用户可以访问和运行包括 Llama 2、Mistral 和 Dolphin Phi 在内的多种大型语言模型。这为开发者和研究者提供了极大的便利。
高度可定制:Ollama 允许用户通过 Modelfile 定义和创建自定义模型,满足特定应用场景的需求。
优化的性能:即使在普通的个人电脑上,Ollama 也能通过优化运行效率,支持运行较小的模型,为用户提供实验和测试的环境。
1、下载安装
第一步先安装工具,官网:https://ollama.com/。Windows就选择安装对于的Windows版本。

直接下载安装即可。只是不能选择安装在哪个盘,下载的模型小的几个G,大的几十个G,默认都安装在C盘了。
2、运行模型
2.1、运行Ollama
安装完成之后,ollama run llama2 运行:

每个模型第一次使用都需要先下载,以通义千问模型为例:
# ollama run 模型名
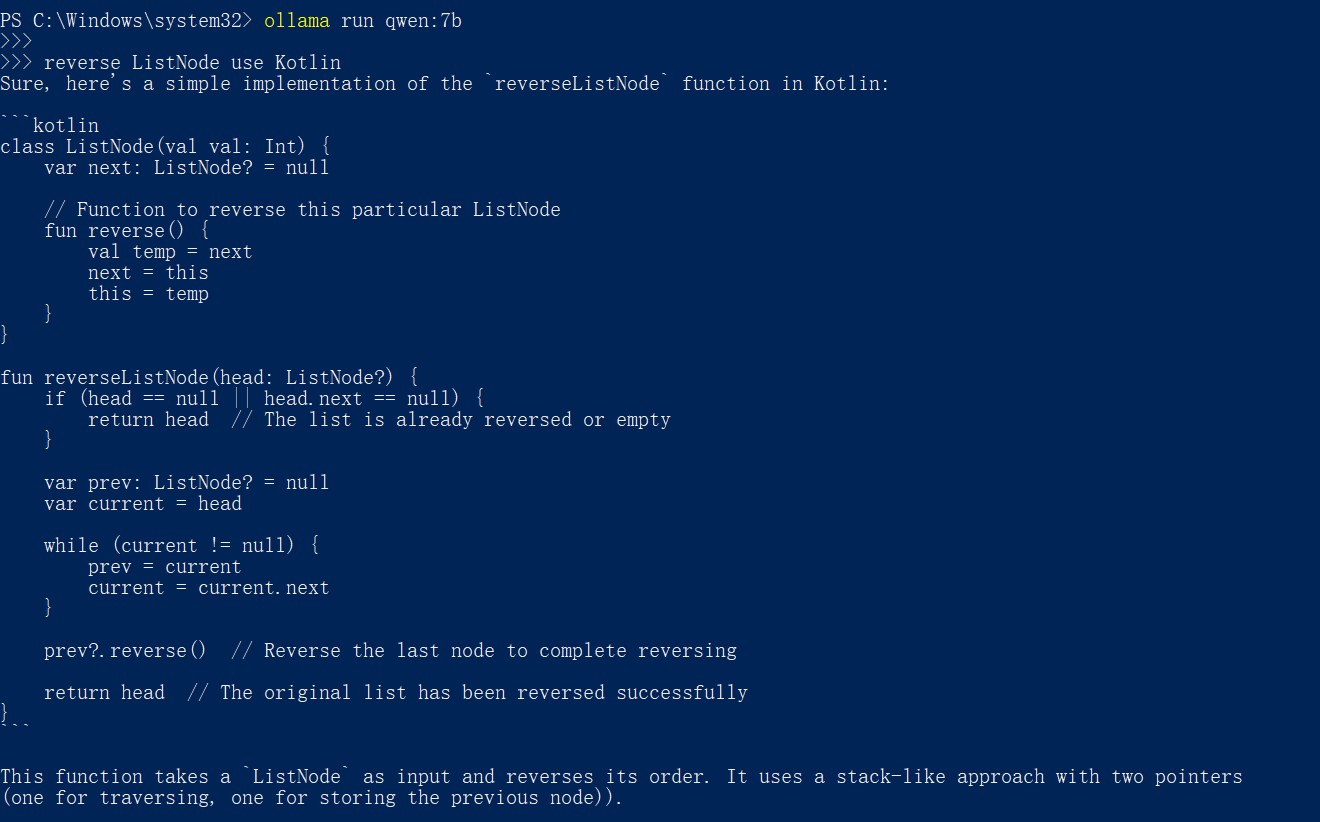
ollama run qwen:7b
时间可能有些长(需要科学加速),后面再运行就不用下载了,直接进入对话环境。

2.2、模型下载
Ollama 提供很多模型,更多模型可以去官网查找下载:https://ollama.com/library。每个都有其特点和适用场景,可以根据自己的需求选择合适的模型进行使用。
Llama 2:这是一个预训练的大型语言模型,具有7B、13B和70B三种不同规模的模型。Llama 2增加了预训练语料,上下文长度从2048提升到4096,使得模型能够理解和生成更长的文本。
OpenHermes:这个模型专注于代码生成和编程任务,适合用于软件开发和脚本编写等场景。
Solar:这是一个基于Llama 2的微调版本,专为对话场景优化。Solar在安全性和有用性方面进行了人工评估和改进,旨在成为封闭源模型的有效替代品。
Qwen:这是一个中文微调过的模型,特别适合处理中文文本。它需要至少8GB的内存进行推理,推荐配备16GB以流畅运行。
不需要很强的显卡运行,即便在CPU上也能运行流畅、问答自如:
2.3、扩展界面*
本地终端的界面或许不友好,已经有很多围绕Ollama的扩展,比如github/open-webui 提供人性化的前端交互界面。

将Ollama部署在服务器上,在搭配这个前端,一个私有AI模型就搭建好了。Ollama 以其易用性、灵活性和强大的功能,为AI爱好者提供一个最简单方便的实现。
精彩的人生需要浪漫、无畏和勇气。